Titanic Kaggle Competition
Predicting Survival of Titanic Disaster
I decided to go through the Introduction to Machine Learning course on my younger brother’s Code Academy account. Thanks Josh!

Some of the things I learned in the course included Linear and Logistic Regression, Decision Trees, K-Nearest Neighbours, K-Means(++) Clustering and the building blocks of deep learning, Perceptrons.
One of the course’s projects was to make a submission to Kaggle’s Titanic competition. After going through the course, I decided to comeback to this project and add to it more of what I learned during the course. Check out the actual submission notebook on Kaggle.com here.
Titanic Competition
In this notebook we’re gonna use multiple types of training models to try and find the best predictor of which passengers will survive the Titanic disaster based on data.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn import linear_model
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import PerceptronAnalysis of the Data
df_train = pd.read_csv("../input/titanic/train.csv")
df_train.head()Going through each feature and making an initial analysis/assumption on their correlation and if we should use them for training the model.
- PassengerID: Not correlated to survival, will not be used in training.
- Pclass: It is likely that passengers of ‘higher class’ were prioritized during the disaster.
- Sex: Women and children were prioritized so this will likely be an important feature for training.
- Name: It is unlikely that name will be useful compared to passenger class.
- Age: Since women and children were prioritized during the rescue, this is definitely a category we will want to look at. Some values are missing so that will have to be cleaned.
- SibSp / Parch: If we add these together it will get the size of your family that was onboard, it’s possible that this could be correlated to survival.
- Ticket: There are too many missing values in ticket, this field will not be used.
- Fare: The fare is correlated with class of the passenger. Since this is the case we will choose the pclass feature.
- Cabin: Again is missing too many values. Will be dropped.
- Embarked: Passengers on the ship may have had their quarters located based on when they embarked in addition to pclass.
df_train["Agebucket"] = pd.cut(df_train['Age'], 8)
age_analysis_df = df_train[['Agebucket', 'Survived']].groupby(['Agebucket'], as_index=False).mean()
age_analysis_df.plot(x='Agebucket', y='Survived', style='o', figsize=(15,5))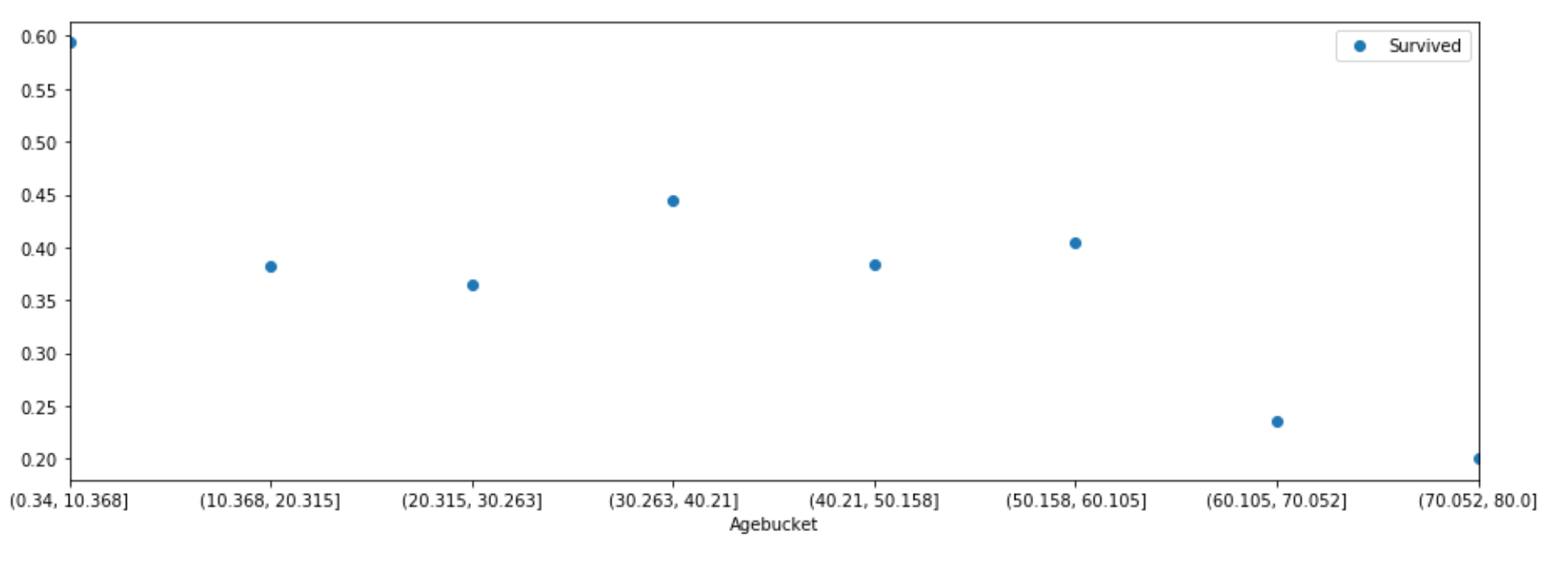
For age we can see that the younger demographic, especially under 10 years old had a better chance of surviving than the other age ranges.
Cleaning the Data for Training
def clean_data(training_dataset):
training_dataset["FirstClass"] = training_dataset["Pclass"].apply(lambda x: 1 if x == 1 else 0)
training_dataset["SecondClass"] = training_dataset["Pclass"].apply(lambda x: 1 if x == 2 else 0)
training_dataset["ThirdClass"] = training_dataset["Pclass"].apply(lambda x: 1 if x == 3 else 0)
training_dataset["SexNum"] = training_dataset["Sex"].map({"male":"0", "female":"1"})
training_dataset["isChild"] = training_dataset["Age"].apply(lambda x: 1 if x != None and x <= 10 else 0)
training_dataset['FamilySize'] = training_dataset['SibSp'] + df_train['Parch'] + 1
training_dataset["embarkedCherbourg"] = training_dataset["Embarked"].apply(lambda x: 1 if x == "C" else 0)
return training_dataset[["SexNum", "isChild", "FirstClass", "SecondClass", "ThirdClass", "embarkedCherbourg"]]classifiers = {
"Logistic Regression" : linear_model.LogisticRegression(),
"K-Nearest Neighbours" : KNeighborsClassifier(2),
"Random Forest" : RandomForestClassifier(),
"Perceptron" : Perceptron()
}
for classifier_name, classifier in classifiers.items():
model = classifier
model.fit(features, survived.values.ravel())
print(classifier_name, model.score(features, survived))Logistic Regression 0.7901234567901234
K-Nearest Neighbours 0.8035914702581369
Random Forest 0.8092031425364759
Perceptron 0.6644219977553311Random Forest performed the best with ~80.9% accuracy on the training data.